
AI
Why should I use AI when working with Data?
Working with large data sets can be very time consuming and often overwhelming. AI thrives on extensive data. Due to several key capabilities, it is...
Like all cleaning, data cleaning may not be fun, but is necessary. It’s the first step when working with data to make it usable. Data often has duplicates, missing information, or is not formatted well for use. The good news is, Querri can help you clean your data much more quickly and with less work.
Let’s look at how. For a good publicly available example of data cleaning, I used the Kaggle FIFA21 dataset (v2). This is a commonly used example of messy data which can be found at Kaggle FIFA21 Data along with several examples of how others have cleaned it (mostly using Python). You can follow in Querri with this data, or load up your own data and get started there.
Data cleaning is a cyclic process that involves exploring the data to better understand it. Here, we focus mostly on the cleaning but will look at analysis more in the future.
Every data set is unique, so while the general steps remain the same, the process is one of exploration and varies from data to data.
The first step when working with data is generally to remove irrelevant information. By removing data we don’t need, we make the rest of the process more efficient. However, we first need to get a general overview of the data.
Example: “Give a brief summary of the columns in the data.”
This gives us a good overview of the data we’re working with.
While the URL’s may be interesting to click through to get more information, they don’t help a lot directly, so let’s drop them. This also helps make the data set a little smaller.
“Drop the photoURL and playerURL columns.”
Depending on what we want to do with the data, we might want to remove others, but will keep for now. There is always a balance between a small data set and retaining information.
Next, we’ll check for duplicates in the data. First, a general check:
Check data for duplicates
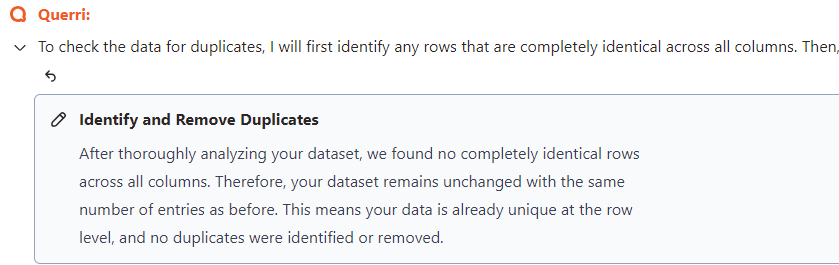
Handling full duplicates is relatively easy as any full duplicated rows could be removed simply by asking Querri to “Remove duplicate rows.” However, for this dataset it’s a bit more complex.
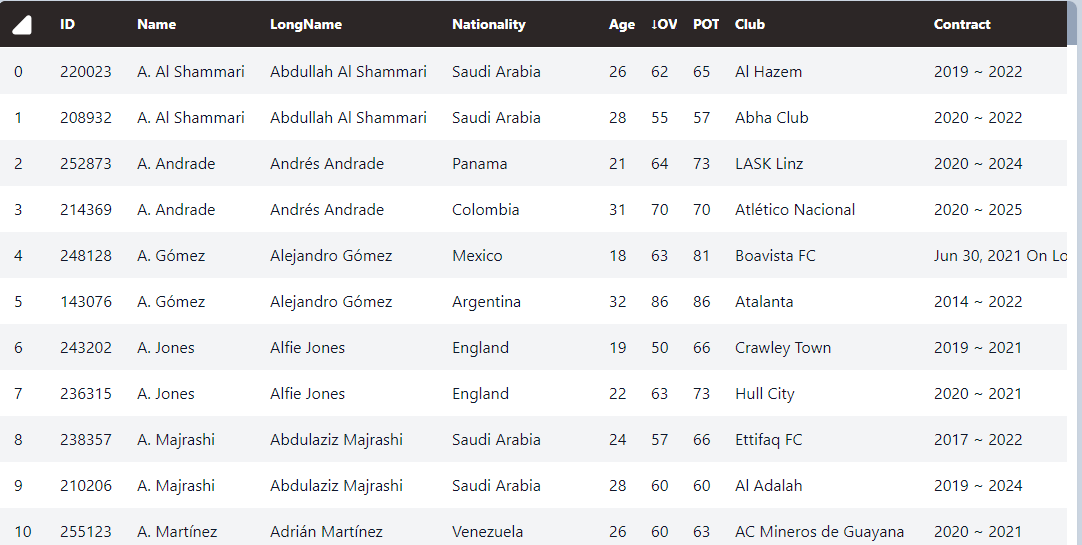
“Check LongName for duplicates.“

In a scenario like this, it’s best to get a better look at this part of the data.
Take all rows with duplicate long names and put them into another sheet. Sort these by name,, longname, and age.
Once Querri does this for me, I can review rows to see what is happening. Since we have the same name with the same contract end but different age, positions, etc these appear to be names for different players so we keep the duplicates.
Looking for missing values with Querri is easy:
Are there any missing values in the data?

This data has no missing values, so is not a good example here. In another blog we’ll look at various ways to handle missing values and how to decide the best process.
Next let’s look at the data in individual columns. Before continuing here we need to make sure we’re back at the full dataset after dropping the URLs by clicking on that tab or in the Data Flow.
The Dataflow can be toggled on and off by clicking the button in the upper right:
Looking down the list, this is the step we want to start from for additional cleaning steps:

Height and Weight are sometimes in Metric and sometimes in English units and are text rather than numeric. Let’s fix that.
Convert Height and Weight to consistently use cm and kg. Add (cm) and (kg) to the column headings.
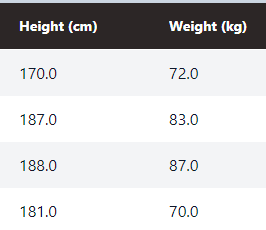
We can see the changed column headings. Depending on the LLM's interpretation of the command it might have left "cm" and "kg" in the cells. In either case, these are integer values stored as float given the ".0" at the end so we'll clean it up.
Convert Height and Weight to integers.
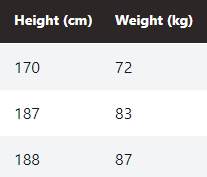
That looks better now.
I often consider when working with Querri how it compares to other tools I have available. Dropping a couple columns is quick and easy in Excel, but going through and converting rows which are stored in inconsistent units using Excel would require either advanced formulas to differentiate and convert correctly, or a lot of manual effort.
Contract, Joined, Loan End
These columns deal with dates but are inconsistent. .
Let’s clean and simplify this:
Add Contract End column after Contract and set it equal to the ending year from Contract.
The Contract Start is duplicated in Joined:
Drop the Contract column.
Let’s put all the date related columns together:
Put the Joined, Contract End, and Loan End columns together and place them after Club.
We now have all these columns together where we want them. Two have full dates while the other has only the year, but that’s as consistent as possible without adding or removing information.
Financial Columns
Value, Wage, and Release clauses are in Euros using ‘M’ and ‘K’. Notation. Let’s convert those to integers.
Remove all 'K' and 'M' notation from Value, Wage, and Release Clause and convert to integer values.
Let’s also convert to USD. Querri can’t access up to date Forex rates itself, but we can provide it with either an additional data set or in the prompt. As of writing, USDEUR is 0.9211
Convert the Euros in Value, Wage, and Release Clause to USD using USDEUR 0.9211.
This is getting better, but those are some very large numbers to display fully. Let’s convert it to show all of them in thousands of USD and add $K to the column headings.
Convert Value, Wages, and Release Clause to 1000's of USD and add ($k) to the column headings.
Better, but still a little messy.
Make those columns integer.
There we go…
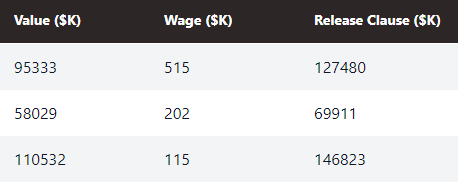
In my first pass through this I used the above steps, but in further testing it could also be done as a single querri:
Remove all 'K' and 'M' notation from Value, Wage, and Release Clause and convert these to integer values in thousands of USD ($K), using USDEUR 0.9211. Add $K to the column headings.

Other Columns
W/F, SM, and IR are star ratings from 1-5. Let’s convert these columns to integers which will drop the star characters.
Convert W/F, SM, and IR to integers.
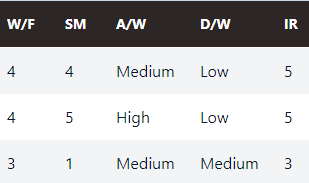
Going back to our summary, A/W and D/W are similar ratings but are rated Low, Medium, High. Let’s convert these to numeric with Low-1, Med-3, High-5 to keep the scale consistent.
Convert A/W and D/W to integers, replacing Low-1, Medium-3, High-5.
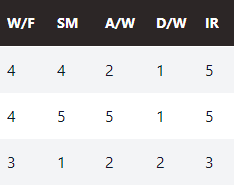
That’s more consistent now.
Hits in some cases has a ‘k’. Let’s also make that into integers. Row 8 as an example:
![]()
Convert Hits to integer.
At this point, the data is pretty clean. Depending on what we want to do with the data, there are other steps we could take, for example, Feature Engineering for using machine learning tools. I’ll look at this more in a future article.
In this article, we go through a large number of relatively simple steps. It is generally possible to put several of these into a single querri and it will execute all of them together. Some can also be reworded to be more general, for example:
Convert financial data to $k (using 0.9211 USDEUR), include this label in those headings, and make anything that looks like a number into an integer.
I’m happy to answer any questions and look forward to the next installment, which will be on visualization.
Working with large data sets can be very time consuming and often overwhelming. AI thrives on extensive data. Due to several key capabilities, it is...
Unlock the hidden potential of your chaotic datasets with Querri's advanced data cleaning and preparation tools.
Querri is an AI-powered data science and analysis assistant designed to help business and operations leaders make smarter decisions through...