चैनल और एजेंट के अनुसार पहली प्रतिक्रिया समय को कैसे ट्रैक और बेहतर करें
Support Ops Leads, CS Managers और QA Leads के लिए बनाया गया। पहचानें कि कौन से एजेंट और चैनल लगातार FRT लक्ष्यों से चूक रहे हैं, और उस विश्लेषण को एक नियमित कोचिंग आधार में बदलें। एक बार के डेटा निष्कर्षण में नहीं।
Querri खोलेंआपको किसकी आवश्यकता होगी
Querri (निःशुल्क ट्रायल) ताकि प्रति टिकट FRT की गणना की जा सके, इसे एजेंट और चैनल के अनुसार एकत्रित किया जा सके, और एक क्रमबद्ध प्रदर्शन तालिका तैयार की जा सके
टिकट/वार्तालाप एक्सपोर्ट (Zendesk, Intercom, Freshdesk या किसी भी हेल्पडेस्क से CSV या Excel) जिसमें टिकट निर्माण का टाइमस्टैम्प, पहली प्रतिक्रिया का टाइमस्टैम्प, असाइन किया गया एजेंट और चैनल (ईमेल, चैट, फ़ोन) शामिल हो
FRT लक्ष्य सीमाएं (चैनल के अनुसार आपका SLA या आंतरिक लक्ष्य, जैसे ईमेल < 4 घंटे, चैट < 2 मिनट)। इनका उपयोग उल्लंघन वाले टिकटों को फ़िल्टर करने और एजेंट्स को लक्ष्य से चूकने के % के अनुसार क्रमबद्ध करने के लिए किया जाता है
मदद चाहिए?
यदि आपके कोई प्रश्न हैं, तो आप डेमो का अनुरोध कर सकते हैं या हमारी टीम को ईमेल कर सकते हैं।
शुरू करने से पहले
अधिकांश टीमें पहले से ही किसी न किसी रूप में FRT को ट्रैक करती हैं। समस्या यह है कि यह आमतौर पर एक बार के उस एक्सपोर्ट में रहता है जिसे किसी ने पिछली तिमाही में निकाला, हर चीज़ पर औसत निकाला, और चुपचाप फ़ाइल कर दिया। यह एक Support Ops Lead को नहीं बताता कि कौन से एजेंट लगातार देर करते हैं। यह एक CS Manager को नहीं बताता कि ईमेल या चैट में से बड़ी समस्या कौन सी है। और यह निश्चित रूप से किसी संरचित तरीके से 1:1 कोचिंग में योगदान नहीं देता।
यह playbook उन Support Ops Leads, CS Managers और QA Leads के लिए है जो FRT विश्लेषण को एक दोहराने योग्य प्रक्रिया में बदलना चाहते हैं। एक ऐसी प्रक्रिया जो प्रति टिकट FRT की गणना करती है, एजेंट और चैनल के अनुसार एकत्रित करती है, उल्लंघन वाले टिकटों को फ़िल्टर करती है, और एक क्रमबद्ध तालिका तैयार करती है जिस पर आपकी टीम हर सप्ताह कार्रवाई कर सकती है।
यह कैसे काम करता है:
- • टिकट निर्माण का टाइमस्टैम्प, पहली प्रतिक्रिया का टाइमस्टैम्प, असाइन किया गया एजेंट और चैनल सहित अपना टिकट/वार्तालाप एक्सपोर्ट अपलोड करें
- • एजेंट और चैनल प्रदर्शन को कवर करने वाली एक संपूर्ण FRT रिपोर्ट तैयार करने के लिए एक ही प्रॉम्प्ट चलाएं
- • उल्लंघन दर को प्रेरित करने वाले सहसंबंधों को खोजने के लिए गहराई में जाएं। Querri से और गहराई से जाँच करने और यह उजागर करने के लिए कहें कि क्या उल्लंघन टिकट मात्रा, दिन के समय, चैनल-एजेंट तालमेल, या स्टाफ़ क्षमता से जुड़े हैं
- • अपनी FRT लक्ष्य सीमाओं के बाहर के टिकटों को फ़िल्टर करें और सीमा का उल्लंघन करने वाले टिकटों के % के अनुसार एजेंट्स की एक क्रमबद्ध तालिका तैयार करें
- • प्रतिबद्ध होने से पहले स्टाफ़ परिवर्तनों, चैनल पुनर्संतुलन, या लक्ष्य समायोजनों के प्रभाव का परीक्षण करने के लिए what-if परिदृश्य चलाएं
- • FRT प्रदर्शन को बेहतर बनाने के लिए Querri से सिफ़ारिशें माँगें और सामान्य सलाह के बजाय प्राथमिकता वाली, डेटा-समर्थित कार्रवाइयाँ प्राप्त करें
- • इसे एक कार्यकारी-स्तरीय प्रस्तुति के साथ समेटें या स्वचालित साप्ताहिक रिपोर्ट शेड्यूल करें ताकि बिना किसी मैन्युअल प्रयास के प्रदर्शन दृश्यमान बना रहे
चरणों का पालन करें
अपना डेटा अपलोड करें
अपने डेटा को Zendesk, Intercom या जिस भी सपोर्ट प्लेटफ़ॉर्म का आप उपयोग करते हैं, उससे CSV या XLSX के रूप में एक्सपोर्ट करें और इसे सीधे Querri में अपलोड करें। फ़ाइल आती है और एक स्वचालित डेटा ऑडिट चलता है, जो टाइमस्टैम्प, एजेंट नामों और चैनल लेबल में गुम मानों, डुप्लिकेट रिकॉर्ड और असंगत प्रारूपों की जाँच करता है।
Querri सादी भाषा की रिपोर्ट में अपनी हर खोज को सामने लाता है ताकि आप ठीक-ठीक देख सकें कि वहाँ क्या है। यदि यह ऐसी समस्याएँ पहचानता है जिन्हें यह ठीक कर सकता है (जैसे दिनांक प्रारूपों को सामान्य करना या पंक्तियों को डीडुप्लिकेट करना), तो यह कोई भी बदलाव करने से पहले आपकी अनुमति माँगता है।
एक बार डेटा साफ़ हो जाने पर, Querri डेटासेट का एक उच्च-स्तरीय सारांश (टिकट मात्रा, चैनल विभाजन, दिनांक सीमा, एजेंट कवरेज) तैयार करता है ताकि किसी भी विश्लेषण के शुरू होने से पहले आपके पास एक स्पष्ट शुरुआती बिंदु हो।
FRT की गणना करें, शोर को फ़िल्टर करें
Querri से प्रत्येक टिकट के लिए FRT को पहली प्रतिक्रिया के टाइमस्टैम्प में से टिकट निर्माण के टाइमस्टैम्प को घटाकर गणना करने के लिए कहें। इससे पहले, महत्वपूर्ण जाँच लागू करें: ऐसे किसी भी टिकट को बाहर कर दें जहाँ कोई पहली प्रतिक्रिया मौजूद नहीं है। अन्यथा बिना मानवीय प्रतिक्रिया वाले, बॉट द्वारा संभाले गए और स्वतः बंद हुए टिकट आपके आँकड़ों को बढ़ा देंगे और धीमे एजेंट्स को उनसे बेहतर दिखाएंगे:
"प्रत्येक टिकट के लिए FRT की गणना पहली प्रतिक्रिया के टाइमस्टैम्प में से निर्माण टाइमस्टैम्प घटाकर करें। ऐसे किसी भी टिकट को बाहर कर दें जहाँ पहली प्रतिक्रिया गुम या null है — ये बॉट द्वारा संभाले गए या स्वतः बंद हुए हैं और इन्हें FRT औसत में नहीं गिना जाना चाहिए।"
Querri शोर वाली पंक्तियों को स्वचालित रूप से चिह्नित और हटा देता है, ताकि आगे से आपकी FRT गणनाएँ केवल वास्तविक मानवीय प्रतिक्रियाओं को ही दर्शाएँ।
पहले आसान उत्तर को खारिज करें
जटिल स्पष्टीकरण खोजने से पहले, स्पष्ट वाले को खारिज कर दें। जब टीमें FRT लक्ष्यों से चूकती हैं, तो पहली प्रवृत्ति हमेशा एक ही होती है: हमें और एजेंट चाहिए। कभी-कभी यह सही होता है। अक्सर नहीं होता। किसी भी तरह, डेटा आपको बता देगा।
"क्या टिकट मात्रा और उल्लंघन दर के बीच कोई सहसंबंध है? इन्हें अवधि के दौरान एक साथ प्लॉट करें।"
इस उदाहरण में, Querri को मूल रूप से कोई सहसंबंध नहीं मिलता। उल्लंघन दर मात्रा के साथ नहीं चलती। यह आपको कुछ महत्वपूर्ण बताता है: टीम पर बोझ नहीं है। और लोग जोड़ने से यह ठीक नहीं होगा। कारण संरचनात्मक है, और आपको और गहराई से देखना होगा।
फिर दिन के समय पर ध्यान दें
यदि मात्रा कारण नहीं है, तो अगली जाँचने योग्य बात यह है कि उल्लंघन कब हो रहे हैं। एकत्रित दैनिक आँकड़े घंटे-दर-घंटे के पैटर्न को धुंधला कर देते हैं, और अधिकांश FRT समस्याएँ उन्हीं पैटर्न के भीतर रहती हैं।
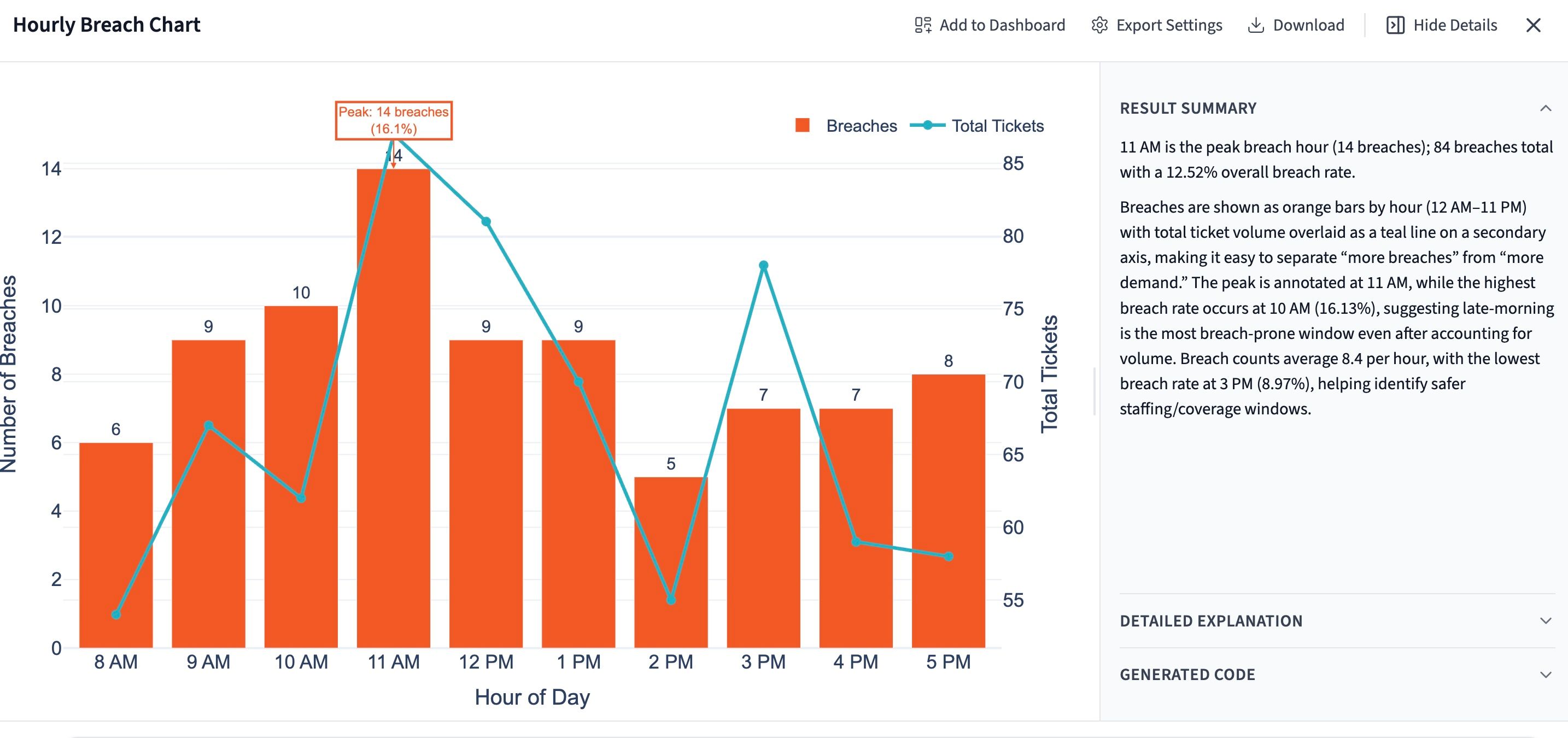
"उल्लंघन दर को दिन के घंटे के अनुसार विभाजित करें। किसी भी चरम उल्लंघन विंडो की पहचान करें और मुझे बताएं कि कुल उल्लंघनों का कितना प्रतिशत उन विंडो में आता है।"
इस उदाहरण में, Querri को सुबह 11 बजे एक तीव्र शिखर मिलता है। सभी उल्लंघनों का लगभग 17% उसी एक घंटे में होता है। यह 60 मिनट की एक विंडो में केंद्रित बहुत सारी परेशानी है, और यह पूरी कोचिंग बातचीत को नए सिरे से परिभाषित कर देता है। सवाल अब यह नहीं रहता कि "ये एजेंट धीमे क्यों हैं?" बल्कि यह हो जाता है कि "सुबह 11 बजे क्या हो रहा है, और क्या यह स्टाफ़, रूटिंग या हैंडऑफ़ की समस्या है?"
सुबह 11 बजे के शिखर का समाधान लगभग कभी कोचिंग नहीं होता। यह लगभग हमेशा शेड्यूलिंग में बदलाव, कोई रूटिंग नियम, या ऊपरी स्तर का कोई हैंडऑफ़ होता है जो चुपचाप टूट रहा होता है। इनमें से कुछ भी आपको एजेंट-दर-एजेंट FRT रिपोर्ट में नहीं मिलेगा।
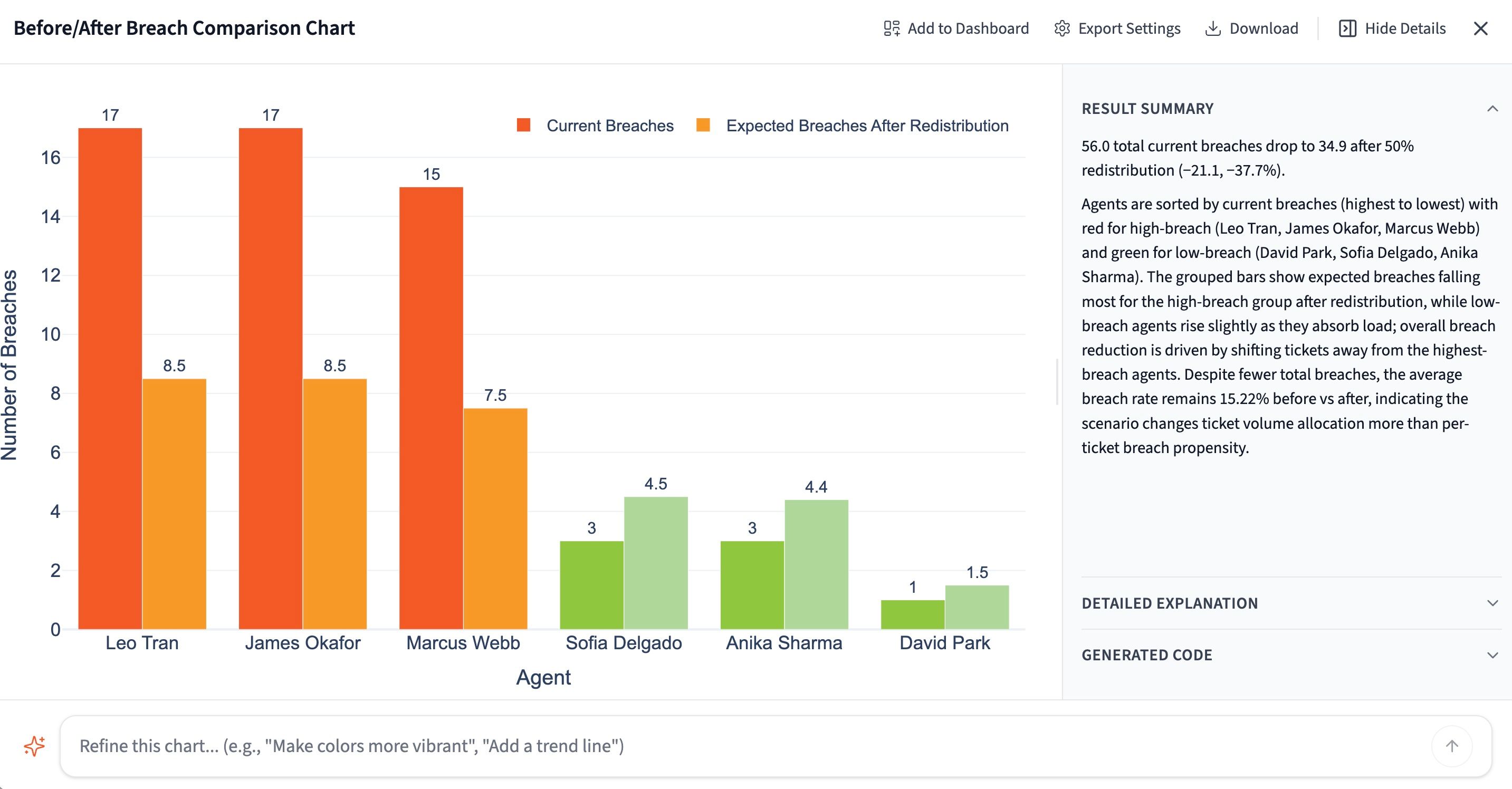
प्रतिबद्ध होने से पहले समाधान का परीक्षण करें
आप जानते हैं कि उल्लंघन कहाँ हैं। अगला सवाल यह है कि इसे ठीक करने से वास्तव में क्या होगा। प्रतिबद्ध होने से पहले इसका परीक्षण करें। Querri से एक सरल पुनर्वितरण मॉडल करने के लिए कहें: यदि 50% टिकट आपके सबसे अधिक उल्लंघन वाले एजेंट्स से सबसे कम वाले एजेंट्स में स्थानांतरित हो जाएँ तो समग्र उल्लंघन दर का क्या होगा?
"यदि सबसे अधिक उल्लंघन दर वाले एजेंट्स से सबसे कम उल्लंघन दर वाले एजेंट्स में 50% टिकट पुनर्वितरित कर दिए जाएँ, तो समग्र उल्लंघन दर पर अनुमानित प्रभाव क्या होगा?"
Querri आपके वास्तविक टिकट डेटा पर परिदृश्य चलाता है और एक अनुमानित नई उल्लंघन दर लौटाता है। अब आपके पास एक स्टाफ़िंग या रूटिंग बातचीत में ले जाने के लिए एक ठोस, बचाव योग्य संख्या है, न कि कोई अंदाज़ा।
जितनी चाहें उतनी विविधताएँ चलाएं। विभिन्न पुनर्वितरण प्रतिशत, विशिष्ट एजेंट्स, या चैनल-स्तरीय पुनर्संतुलन आज़माएं जब तक कि आपको ऐसा परिदृश्य न मिल जाए जो संख्या को बदले और जिसके लिए वास्तव में स्टाफ़ रखना यथार्थवादी हो।
Querri को सिफ़ारिशें लिखने दें
FRT सुधारने के बारे में अधिकांश लेख आपको वही तीन सुझाव देते हैं: और एजेंट रखें, अधिक समझदारी से रूट करें, बेहतर प्रशिक्षण दें। सिद्धांत में उपयोगी। बेकार जब आप सुबह 11 बजे के किसी विशिष्ट उल्लंघन पैटर्न को देख रहे हों और यह तय करने की कोशिश कर रहे हों कि समाधान शेड्यूलिंग में बदलाव है या कोचिंग में। तो सामान्य playbook को छोड़ दें। बस Querri से पूछें।
"आपने जो कुछ भी पाया है, उसके आधार पर हमारे FRT प्रदर्शन को बेहतर बनाने के लिए आपकी शीर्ष सिफ़ारिशें क्या हैं?"
Querri को पहले से ही पता है कि आपके उल्लंघन कहाँ केंद्रित हैं, दिन के समय के कौन से पैटर्न मौजूद हैं, और पुनर्वितरण का क्या प्रभाव होगा। इसलिए इसकी सिफ़ारिशें शून्य से शुरू नहीं होतीं। वे सीधे आपके डेटा से जुड़ी होती हैं, और गणित के अनुसार प्राथमिकता दी जाती हैं, न कि इस आधार पर कि किसी बैठक में सबसे अधिक बचाव योग्य क्या लगता है।
किसी भी सिफ़ारिश में फ़ॉलो-अप प्रॉम्प्ट के साथ गहराई तक जाएं। Querri से इसके तर्क को समझाने, प्रभाव का आकलन करने, या यह पहचानने के लिए कहें कि यह किन टीम सदस्यों या चैनलों पर सबसे अधिक लागू होती है।

इसे QBR में ले जाएं
साप्ताहिक FRT डेटा आपको बताता है कि अभी क्या हो रहा है। तिमाही डेटा आपको बताता है कि आप इसके बारे में जो कुछ भी कर रहे हैं वह वास्तव में काम कर रहा है या नहीं, और यही वह सवाल है जिसका जवाब आपका CFO चाहता है। तीन महीने के टिकट एक्सपोर्ट को Querri में लाएं और QBR संस्करण माँगें:
"इस तिमाही के डेटा का उपयोग करते हुए, FRT प्रदर्शन पर एक QBR-तैयार प्रस्तुति तैयार करें। इसमें मुख्य निष्कर्ष, प्रवृत्ति विश्लेषण, हमारे द्वारा पहचाने गए मुख्य उल्लंघन कारक, और अगली तिमाही के लिए हमारी शीर्ष सिफ़ारिशें शामिल करें।"
Querri एक संरचित प्रस्तुति तैयार करता है जिसे आपकी टीम सीधे किसी नेतृत्व समीक्षा में ले जा सकती है। उल्लंघन प्रवृत्तियाँ, मूल कारण सारांश, what-if परिदृश्य परिणाम, और एक प्राथमिकता वाली कार्य योजना, सब एक ही जगह। कोई मैन्युअल फ़ॉर्मेटिंग नहीं, किसी खाली स्लाइड से शुरुआत नहीं।
FRT को QBR में लाना इसे एक परिचालन मीट्रिक से एक रणनीतिक मीट्रिक में बदल देता है। शिकायतों पर बाद में प्रतिक्रिया देने के बजाय, नेतृत्व को स्टाफ़, टूलिंग, या SLA लक्ष्यों पर निर्णय लेने के लिए संदर्भ मिलता है।
बेहतर FRT रिपोर्टिंग के लिए सुझाव
FRT की गणना करने से पहले हमेशा बिना पहली प्रतिक्रिया वाले टिकटों को फ़िल्टर कर दें
यह किसी भी FRT विश्लेषण में सबसे महत्वपूर्ण डेटा गुणवत्ता चरण है, और यही वह चरण है जिसे अधिकांश टीमें छोड़ देती हैं। पहली प्रतिक्रिया का null टाइमस्टैम्प मतलब किसी बॉट, किसी ऑटो-क्लोज़ नियम, या किसी स्व-सेवा प्रवाह ने वार्तालाप को संभाला। किसी मानव ने उसे कभी नहीं छुआ। उन पंक्तियों को अपने औसत में शामिल करना ऐसा है जैसे आप मापें कि आपकी बिक्री टीम कितनी तेज़ी से सौदे बंद करती है, उन सभी लीड्स को गिनकर जिन्हें उसने कभी कॉल ही नहीं किया। संख्या बेहतर हो जाती है, लेकिन वह किसी वास्तविक चीज़ का वर्णन करना बंद कर देती है। जिन टीमों का FRT डेटा सबसे बुरा दिखता है, वे कभी-कभी वही होती हैं जो सबसे ईमानदार हिसाब रखती हैं। इस फ़िल्टर को हर बार अपने मानक प्रॉम्प्ट का हिस्सा बनाएं।
उल्लंघन दर के अनुसार क्रमबद्ध करें, और उसके साथ माध्यिका + p90 रिपोर्ट करें
औसत FRT धोखा देता है। एक ही रात भर का टिकट पूरे सप्ताह को विकृत कर सकता है। कोचिंग के लिए आपको वास्तव में जो चाहिए वह है टिकटों का वह प्रतिशत जिनमें किसी एजेंट ने सीमा पार की, माध्यिका (सामान्य अनुभव), और p90 (आपके सबसे धीमे 10% ग्राहक किससे जूझ रहे हैं)। तेज़ माध्यिका और ऊँचे p90 वाली टीम में एक टेल समस्या होती है जिसे औसत छिपा रहा होता है। तीनों को सामने लाएं।
एजेंट्स की तुलना उनके चैनल के भीतर करें, चैनलों के आर-पार नहीं
चैट एजेंट हमेशा ईमेल एजेंट्स की तुलना में तेज़ दिखेंगे। अलग SLA, अलग ग्राहक अपेक्षाएँ, पूरी तरह अलग काम। और जब आप ऐसा कर ही रहे हैं, तो क्रमबद्ध तालिका को टिकट मात्रा के संदर्भ के साथ जोड़ें: जिस एजेंट ने 8 टिकट संभाले और 3 चूका, वह उससे बहुत अलग स्थिति में है जिसने 200 संभाले और 70 चूके। मात्रा बातचीत के ढाँचे को पूरी तरह बदल देती है।
इसे नियमित बनाएं, प्रतिक्रियात्मक नहीं
एक बार का निष्कर्षण आपको बताता है कि पिछले महीने कौन धीमा था। एक साप्ताहिक शेड्यूल की गई रिपोर्ट आपको बताती है कि कुछ बदल रहा है या नहीं। अपने Querri प्रोजेक्ट को एक टेम्पलेट के रूप में सहेजें और इसे शेड्यूल पर चलाएं।
अक्सर पूछे जाने वाले प्रश्न
इस विश्लेषण के लिए मुझे कौन सा डेटा अपलोड करना होगा?
जब मैं अपनी फ़ाइल अपलोड करता हूँ तो Querri के डेटा ऑडिट के दौरान क्या होता है?
Querri FRT की गणना करने से पहले बिना पहली प्रतिक्रिया वाले टिकटों को फ़िल्टर क्यों कर देता है?
Querri को टिकट मात्रा और उल्लंघन दर के बीच बहुत कम सहसंबंध मिला। इसका क्या मतलब है?
Querri में what-if परिदृश्य कैसे काम करते हैं?
Querri की सिफ़ारिशें सामान्य सर्वोत्तम-अभ्यास सलाह से कैसे भिन्न हैं?
Querri द्वारा तैयार FRT पर एक QBR प्रस्तुति में क्या होता है?
मुझे यह विश्लेषण कितनी बार चलाना चाहिए?
अन्य लोकप्रिय संसाधन
उदाहरण
सभी उपयोग के मामले देखें
जानें कि अन्य टीमें डेटा विश्लेषण के लिए Querri का उपयोग कैसे करती हैं।
ब्लॉग
एजेंटिक AI कैसे काम करता है
जानें कि Querri के AI एजेंट आपके डेटा विश्लेषण को कैसे बदलते हैं।
डेमो
एक वॉकथ्रू का अनुरोध करें
अपने स्वयं के डेटा के साथ Querri को क्रिया में देखें।
मूल्य निर्धारण
योजनाओं की तुलना करें
व्यक्तियों, टीमों या एंटरप्राइज़ के लिए सही योजना खोजें।