So analysieren Sie die Treiber des Ticketvolumens, um wiederholte Kontakte zu reduzieren
Ermitteln Sie, welche Ticketkategorien die meisten wiederholten Kontakte verursachen, quantifizieren Sie das Deflection-Potenzial und kommen Sie mit Zahlen statt Bauchgefühl zu Ihrem nächsten Planungsmeeting.
Querri öffnenWas Sie benötigen
Querri (Kostenlose Testversion) um Ihre Ticketdaten zu verbinden, die Analyse auszuführen und die Deflection-Chancen-Tabelle zu erstellen
Supportticket-Export — CSV aus Zendesk, Intercom, Freshdesk oder Salesforce Service Cloud mit Betreff-/Grund-Tag, Kategorie, Produktbereich, Erstellungsdatum und Lösungsart
Optional: KB-Artikel-Aufrufe — ein separater Export mit Artikeltitel, Artikel-ID und Aufrufzahl (erforderlich für Schritt 5)
Brauchen Sie Hilfe?
Wenn Sie Fragen haben, können Sie eine Demo anfordern oder unserem Team schreiben.
Bevor wir beginnen
Das teuerste Ticket ist das zweite zum selben Anliegen. Wiederholte Kontakte zehren an der Personalkapazität, drücken den CSAT und signalisieren, dass etwas Vorgelagertes (ein Produktreibungspunkt, eine Lücke in der Wissensdatenbank, ein defekter Prozess) nicht behoben wird.
Das Problem ist selten die Motivation. Die meisten Support-Verantwortlichen wollen die Ursachen angehen. Das Problem sind Belege: zu wissen, welche Kategorien das meiste Wiederholungsvolumen erzeugen, wie sich das mit dem Trend vergleicht und wo Self-Service vorhanden sein sollte, es aber nicht ist. Dieses Playbook zeigt Ihnen, wie Sie diese Belege erhalten: ausgehend von einem rohen Ticketexport, endend mit einem Balkendiagramm und einer priorisierten Deflection-Chancen-Tabelle, auf die Ihr Team reagieren kann.
So funktioniert es:
- • Verbinden Sie einen CSV-Export aus Ihrem Helpdesk (Zendesk, Intercom, Freshdesk, Salesforce Service Cloud) oder nutzen Sie eine Live-Data-Connection
- • Führen Sie fünf Prompts aus, um von rohen Ticketdaten zu einer Volumenaufschlüsselung nach Kategorie, der Trendrichtung und einer Deflection-Chancen-Tabelle zu gelangen
- • Wenn Ihre Tags inkonsistent oder stark auf "Other" konzentriert sind, nutzen Sie das Categorize-Tool, um echte Muster im Tickettext selbst zu finden – für den Anfang ist keine saubere Taxonomie nötig
- • Verknüpfen Sie optional KB-Artikel-Aufrufdaten, um Self-Service-Lücken zu identifizieren: Kategorien, in denen Kunden den Support kontaktieren, aber in Ihrem Hilfecenter keine Antworten finden
- • Exportieren Sie nach Excel und bringen Sie eine priorisierte Tabelle zu Ihrem nächsten Roadmap- oder Content-Planungsmeeting mit
Folgen Sie den Schritten
Laden Sie Ihre Ticketdaten hoch
Laden Sie zunächst einen CSV-Export aus Ihrem Helpdesk hoch: Zendesk, Intercom, Freshdesk oder Salesforce Service Cloud funktionieren alle. Querri profiliert die Datei automatisch und bereitet sie für die Analyse vor. Keine Neuformatierung erforderlich.
Wenn Ihr Helpdesk eine direkte Datenverbindung unterstützt, sehen Sie sich die Integrationsseite von Querri an; verbundene Quellen bleiben ohne manuelle Exporte aktuell.
Erforderliche Spalten: Betreff-/Grund-Tag, Kategorie, Produktbereich, Erstellungsdatum und Lösungsart. Kunden-ID oder E-Mail ist optional, aber für die Analyse wiederholter Kontakte im Abschnitt „Tiefer einsteigen“ weiter unten erforderlich.
Gruppieren und zählen Sie Tickets nach Kategorie und Tag über ein gleitendes 90-Tage-Fenster
Wenn Ihre Daten verbunden sind, führen Sie diesen Prompt aus, um Ihre Volumen-Ausgangsbasis zu erhalten: welche Kategorie-Tag-Kombinationen im letzten Quartal die meisten Kontakte erzeugen.
"Gruppiere die Tickets nach Kategorie und Betreff-/Grund-Tag über ein gleitendes 90-Tage-Fenster. Zeige die Gesamtzahl der Tickets je Kombination an, sortiert nach Volumen absteigend."
Warum 90 Tage? Lang genug, um wöchentliche Schwankungen zu glätten, kurz genug, um die aktuelle Produkt- und Prozessrealität widerzuspiegeln. Das ist Ihre Ausgangsbasis vor allem anderen.
Ermitteln Sie die Top-10-Kategorien nach Volumen und Trendrichtung
Volumen allein sagt Ihnen nicht, worauf Sie sich konzentrieren sollten. Das Hinzufügen der Trendrichtung zeigt, welche Kategorien wachsen und welche sich stabilisieren – was Ihre Priorisierung verändert.
"Ermittle aus den Ticketdaten die Top-10-Kategorien nach gesamtem Ticketvolumen der letzten 90 Tage. Berechne für jede Kategorie das Volumen der jüngsten 30 Tage im Vergleich zu den 30 Tagen davor und kennzeichne den Trend als Steigend, Stabil oder Fallend."
Eine stabile Kategorie mit hohem Volumen ist ein Kandidat für Deflection-Investitionen. Eine, die im letzten Monat um 40 % gestiegen ist, erfordert womöglich sofortige Untersuchung. Die Trendkennzeichnung ist Ihre Art, Prioritäten zu setzen.
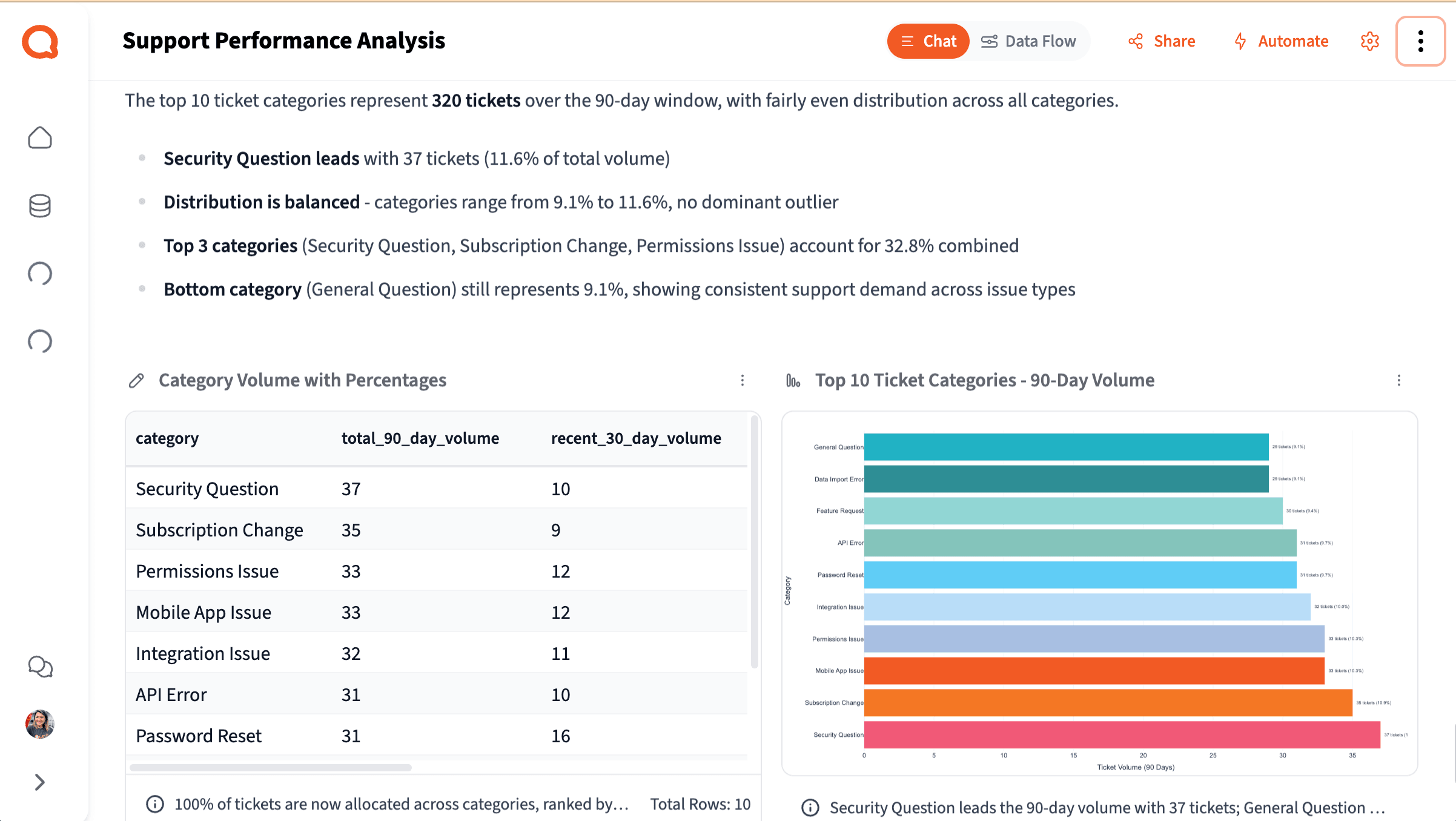
Berechnen Sie den prozentualen Anteil jeder Kategorie am Gesamtvolumen
Das ist Ihr primäres Ausgabe-Visual: ein Balkendiagramm, das die Frage beantwortet, mit der jedes Deflection-Gespräch beginnt: "Was lösen wir eigentlich und wie groß ist jeder Teil?"
"Berechne für die Top-10-Ticketkategorien, welchen Prozentsatz des gesamten Ticketvolumens jede einzelne über das 90-Tage-Fenster ausmacht. Stelle dies als nach Volumen sortiertes Balkendiagramm dar, mit dem Prozentwert an jedem Balken."
Exportieren Sie anschließend die Deflection-Chancen-Tabelle: Bitten Sie Querri, die Top-10-Kategorien mit Volumen, Trendrichtung, geschätztem Deflection-Potenzial (Hoch / Mittel / Niedrig) und empfohlener Maßnahmenart (KB-Artikel, In-App-Anleitung, Produktkorrektur oder Prozessänderung) zu formatieren und nach Excel zu exportieren. Bringen Sie sie zu Ihrem nächsten Roadmap- oder Content-Planungsmeeting mit.
Plausibilitätsprüfung: Notieren Sie, welcher Prozentsatz der Tickets als "Other" oder "General" markiert ist. Wenn es 30 % oder mehr sind, kennzeichnen Sie das in Ihrer Ausgabe: Dem Diagramm fehlt Signal. Im Abschnitt „Tiefer einsteigen“ weiter unten erfahren Sie, wie Sie es zurückgewinnen.
Verknüpfen Sie KB-Artikel-Aufrufdaten, um Kategorien mit hohem Volumen und geringer Self-Service-Nutzung sichtbar zu machen
Dieser Schritt macht die klarsten Deflection-Chancen sichtbar: Kategorien, zu denen Kunden den Support kontaktieren, für die sie aber in Ihrem Hilfecenter keine Antworten finden.
"Verbinde die Aufrufdaten der Wissensdatenbank-Artikel. Verknüpfe sie mit den Top-Ticketkategorien aus der Supportticket-Analyse. Ermittle für jede Kategorie mit hohem Volumen, ob ein passender KB-Artikel existiert und wie oft er im selben 90-Tage-Zeitraum aufgerufen wurde. Markiere Kategorien, in denen das Ticketvolumen hoch ist, die KB-Artikel-Aufrufe aber niedrig sind oder kein Artikel existiert."
Eine Kategorie mit hohem Volumen und null oder nahezu null KB-Aufrufen ist ein starkes Signal dafür, dass der Inhalt entweder nicht existiert, nicht auffindbar ist oder das Problem nicht löst. Dorthin sollte Ihre Content-Investition zuerst fließen.
Verwandeln Sie Ihre Analyse in eine Präsentation. Wenn Sie fertig sind, bitten Sie Querri, sie als Foliensatz aufzubereiten; es führt Ihre Diagramme, die Kategorienaufschlüsselung und die Deflection-Chancen-Tabelle zu einer strukturierten Präsentation zusammen, die Sie direkt mit Ihrem Team oder der Führungsebene teilen können.
Tiefer einsteigen
Geben Sie einzelnen Tickets Struktur
Tiefer einsteigen
Geben Sie einzelnen Tickets Struktur
Die fünf Schritte oben liefern Ihnen aggregierte Muster: welche Kategorien, wie viel Volumen, welche Trends. Wenn Sie Zeile für Zeile vorgehen und verstehen möchten, was auf Ebene des einzelnen Tickets passiert, geben Ihnen die Tools Researcher und Categorize drei zusätzliche Optionen.
Klassifizieren Sie Tickets nach Self-Service-Potenzial
Das aggregierte Deflection-Potenzial in Schritt 4 ist eine Schätzung. Der Researcher wendet diese Klassifizierung Zeile für Zeile auf den tatsächlichen Ticketinhalt an und liefert Ihnen eine besser belegbare Zahl dafür, wie viel Volumen wirklich deflektierbar ist.
"Füge jedem Ticket eine Spalte 'Self-Service-Potenzial' hinzu und klassifiziere es als: Vollständig selbstlösbar, Teilweise selbstlösbar oder Agent erforderlich."
Markieren Sie wiederholte Kontakte auf Ticketebene
Sobald sie markiert sind, können Sie nur nach wiederholten Kontakten filtern und beliebige der obigen Prompts auf diese Teilmenge anwenden. Einige Kategorien haben ein geringes Gesamtvolumen, aber sehr hohe Wiederholungsraten – was bedeutet, dass das Problem systematisch nicht gelöst wird.
"Füge eine Spalte 'Wiederholter Kontakt' hinzu, die jedes Ticket eines Kunden markiert, der innerhalb der vorangegangenen 7 Tage ein Ticket in derselben Kategorie eingereicht hat. Kennzeichne markierte Tickets mit Ja und füge die ursprüngliche Ticket-ID hinzu."
Gewinnen Sie Signal aus unordentlichen oder Sammel-Tags zurück
Wenn Ihre Plausibilitätsprüfung ein erhebliches Volumen an "Other" oder "General" ergeben hat, ist dies der Weg zur Wiederherstellung. Categorize liest den rohen Tickettext und findet natürliche Gruppierungen, ohne dass Sie zuerst die Kategorien definieren müssen.
"Was sind die Hauptthemen in den Ticketbeschreibungen der Tickets, die derzeit als 'Other' oder 'General' markiert sind?"
Tipps für eine bessere Analyse
Prüfen Sie die Tag-Hygiene, bevor Sie beginnen
Bevor Sie aus Ihrer Kategorienaufschlüsselung Schlüsse ziehen, prüfen Sie, welcher Prozentsatz der Tickets in "Other" oder einer Sammelkategorie liegt. Wenn es 30 % oder mehr sind, vermerken Sie das ausdrücklich in Ihrer Ausgabe und nutzen Sie das Categorize-Tool, um das fehlende Signal zurückzugewinnen – warten Sie aber nicht auf eine perfekte Taxonomie, um zu beginnen.
Nutzen Sie das 90-Tage-Fenster als Ihre Standard-Ausgangsbasis
Das 90-Tage-Fenster glättet wöchentliche Schwankungen und spiegelt zugleich die aktuelle Realität wider. Kürzere Fenster sind verrauschter; längere können kürzliche Produkt- oder Prozessänderungen verdecken, die das Volumen aktiv nach oben oder unten treiben.
Bringen Sie die Tabelle mit, nicht nur das Diagramm
Das Balkendiagramm beantwortet „was wir lösen“. Die Deflection-Chancen-Tabelle beantwortet „was wir dagegen tun“. Beides ist für ein produktives Planungsmeeting nötig. Teilen Sie das eine nicht ohne das andere.
Produktprobleme sind großartige Ergebnisse, keine Fehlschläge
Wenn die Analyse auf ein Produktproblem statt auf eine Content-Lücke hinweist, ist das das bestmögliche Ergebnis: Es gibt Ihrem Team quantifizierte Belege für das Engineering an die Hand, nicht nur Anekdoten. Der Export ist genau für dieses Gespräch gemacht.
Tags sind ein Ausgangspunkt, keine Voraussetzung
Sie brauchen keine saubere Taxonomie, um zu beginnen. Selbst wenn die Tags inkonsistent sind, kann Querri aus dem rohen Tickettext echte Muster finden. Nutzen Sie das Categorize-Tool für beliebige Sammelkategorien, um sichtbar zu machen, was tatsächlich darin steckt, und verbessern Sie anschließend die Tagging-Praxis für die Zukunft.
Führen Sie es monatlich aus; machen Sie quartalsweise eine vollständige Überprüfung
Sobald Sie es das erste Mal ausgeführt haben, dauern Folgeläufe unter 10 Minuten. Monatlich prüfen Sie, ob sich Trends verschoben haben. Quartalsweise führen Sie eine vollständige Überprüfung der Deflection-Chancen durch, um zu beurteilen, ob sich Ihre Investitionen in den Zahlen niederschlagen.
Häufig gestellte Fragen
Wie reduziere ich wiederholte Kontakte im Kundensupport?
Wie identifiziere ich die Ursachen für ein hohes Supportticket-Volumen?
Was ist die Deflection-Rate im Kundensupport und wie verbessere ich sie?
Wie baue ich anhand von Ticketdaten einen Business Case für Investitionen in Wissensdatenbank oder Self-Service auf?
Wie analysiere ich Supportticket-Trends, um zu priorisieren, worauf ich mich konzentriere?
Weitere beliebte Ressourcen
Beispiele
Alle Anwendungsfälle durchsuchen
Entdecken Sie, wie andere Teams Querri für die Datenanalyse nutzen.
Blog
NPS-Antworten in großem Maßstab analysieren
Vom Umfragechaos zu klaren Themen: eine praktische Anleitung.
Demo
Eine Vorführung anfordern
Sehen Sie Querri mit Ihren eigenen Daten in Aktion.
Blog
Unstrukturierten Text verständlich machen
Wie Sie offene Ticket- und Umfragedaten wirklich analysieren.